Extraire des données
Extraction de données
C’est l’endroit où il vous suffit de choisir un grand nombre de fichiers PDFs, et où PDFZone extrait automatiquement vos données.
Comment extraire des données?
Note : vous devez avoir préalablement configuré des Champs et des Modèles
- Glissez et déposez (Drag & Drop) vos fichiers PDF ou cliquez sur le bouton
 situé en bas à gauche de la fenêtre, ensuite choisissez vos fichiers PDF
situé en bas à gauche de la fenêtre, ensuite choisissez vos fichiers PDF - Cliquez sur le bouton
 dans la barre d’outils située au dessus de la fenêtre, cela démarrera le processus d’extraction.
dans la barre d’outils située au dessus de la fenêtre, cela démarrera le processus d’extraction.
Observez les résultats s’afficher au fur et à mesure.
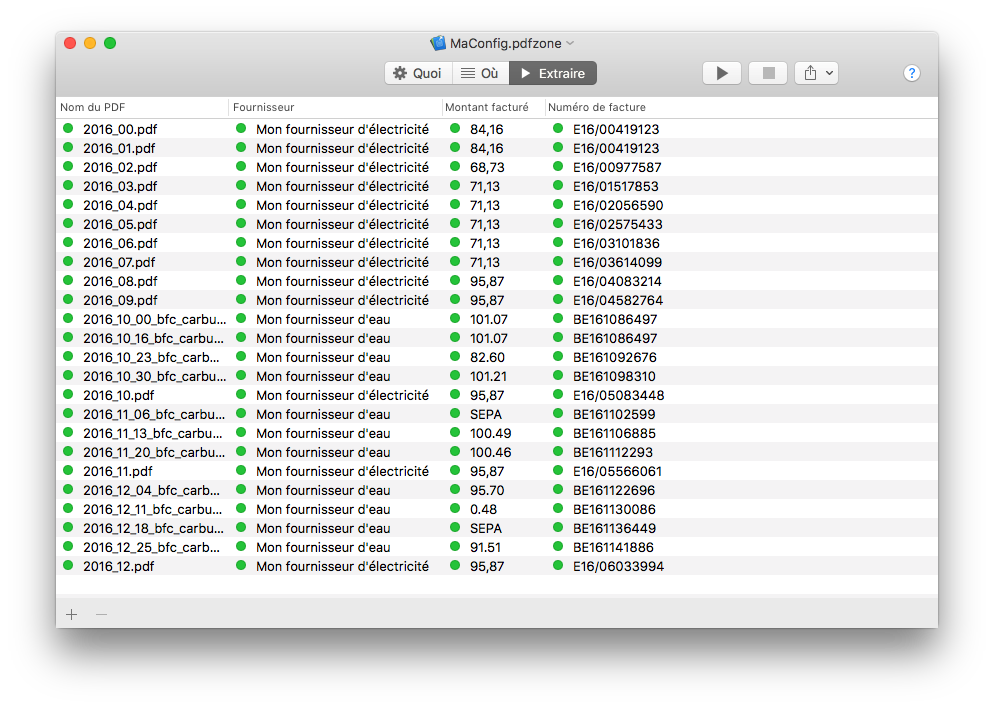 Si le nom du Modèle indique : “!! Document non-OCR !!”, c’est que le fichier PDF n’est pas passé par de la reconnaissance de texte, et ne contient que des images aux yeux de PDFZone. Vous devez alors passer votre PDF dans un logiciel de reconnaissance de caractères.
Si le nom du Modèle indique : “!! Document non-OCR !!”, c’est que le fichier PDF n’est pas passé par de la reconnaissance de texte, et ne contient que des images aux yeux de PDFZone. Vous devez alors passer votre PDF dans un logiciel de reconnaissance de caractères.
Et ensuite ?
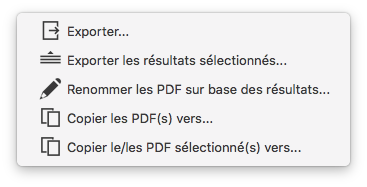
Vous pouvez exportez les données extraites en cliquant sur le bouton Exporter ![]() dans la barre d’outils située au dessus de la fenêtre.
PDFZone offre alors les choix suivants:
dans la barre d’outils située au dessus de la fenêtre.
PDFZone offre alors les choix suivants:
- Exporter les résultats
- Exporter seulement les résultats sélectionnés dans la table. Pour sélectionner plusieurs résultats, appuyez sur la touche Command (⌘) du clavier et cliquez sur les résultats de votre choix.
- Renommer les fichiers sources sur base des résultats (valeurs extraites)
- Copier les fichiers vers… : PDFZone fera une copie des fichiers PDF dont l’extraction (selon votre choix) a réussi/partiellement réussi/échoué. Le dossier de destination vous sera demandé.
- Copier les fichiers sélectionnés vers… : PDFZone copiera les fichiers sélectionnés vers le répertoire de votre choix.